apt update & upgrade は日常的に実行するものですが、忙しかったりすると疎かになりがちです。そこで unattended-upgrades を有効にしておくことで、j自動で更新を行えます。
インストール
$ sudo apt install unattended-upgrades
Reading package lists… Done
Building dependency tree
Reading state information… Done
Suggested packages:
bsd-mailx needrestart
The following NEW packages will be installed:
unattended-upgrades
0 upgraded, 1 newly installed, 0 to remove and 1 not upgraded.
Need to get 61.7 kB of archives.
After this operation, 252 kB of additional disk space will be used.
Get:1 http://http.us.debian.org/debian stretch/main amd64 unattended-upgrades all 0.93.1+nmu1 [61.7 kB]
Fetched 61.7 kB in 0s (82.8 kB/s)
Preconfiguring packages …
Selecting previously unselected package unattended-upgrades.
(Reading database … 38885 files and directories currently installed.)
Preparing to unpack …/unattended-upgrades_0.93.1+nmu1_all.deb …
Unpacking unattended-upgrades (0.93.1+nmu1) …
Processing triggers for systemd (232-25+deb9u6) …
Setting up unattended-upgrades (0.93.1+nmu1) …
Processing triggers for man-db (2.7.6.1-2) …
インストール後に dpkg-reconfigure で有効化します。
有効化
$ sudo dpkg-reconfigure unattended-upgrades
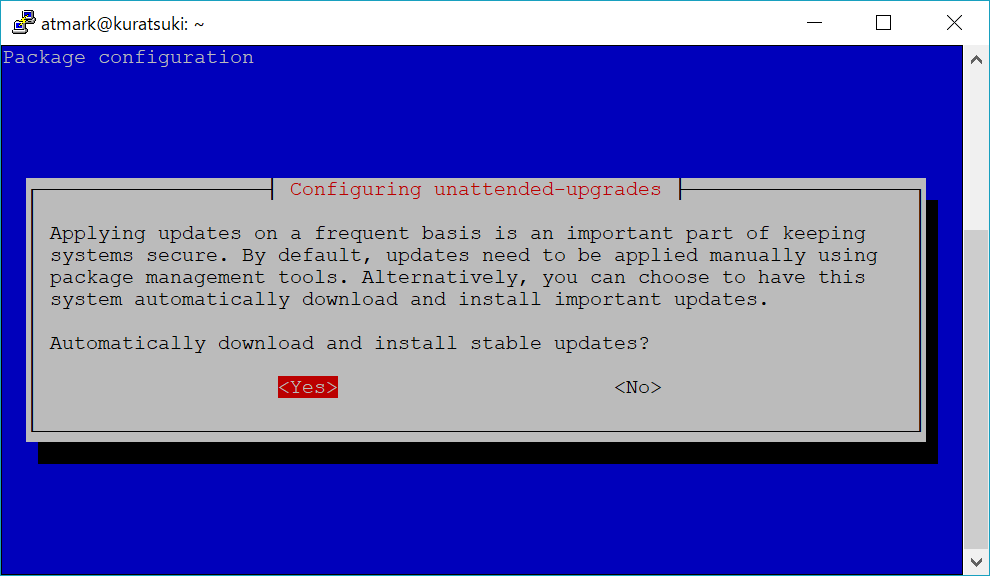
自動更新の対象とするパッケージの指定です。
autoremove の設定
/etc/apt/apt.conf.d/50unattended-upgrades を編集し、不要になったパッケージの削除を有効にします。
// ...略...
Unattended-Upgrade::Remove-Unused-Dependencies "true";
// ...略...
/etc/apt/apt.conf.d/20auto-upgrades に以下を追記し、autoremove の実行間隔を設定します。
APT::Periodic::AutocleanInterval "1";
ここの単位は「日」ですので、”1″ であれば 1 日毎に実行、”0″ なら無効になります。
// Do “apt-get autoclean” every n-days (0=disable)
UnattendedUpgrades – Debian Wiki
APT::Periodic::AutocleanInterval “21”;
メール通知
mailx コマンドでメールが送れることを確認しておきましょう。
$ sudo apt install mailutils
/etc/apt/apt.conf.d/50unattended-upgrades を編集し、 次の一行を編集して有効にします。
Unattended-Upgrade::Mail "[email protected]";
エラーの時のみメール通知する場合は、次の一行も編集します。
Unattended-Upgrade::MailOnlyOnError "true";
動作確認
root で unattended-upgrades を実行すれば実際の動作を確認できます。-d(–debug) オプションを付けると処理内容を表示してくれます。
$ sudo unattended-upgrade -d
Initial blacklisted packages:
Initial whitelisted packages:
Starting unattended upgrades script
Allowed origins are: ['origin=Debian,codename=stretch']
pkgs that look like they should be upgraded:
Fetched 0 B in 0s (0 B/s)
fetch.run() result: 0
blacklist: []
whitelist: []
No packages found that can be upgraded unattended and no pending auto-removals