$ sed '1c 置換え後の内容'
find と組合せて、拡張子が .cgi であるファイルの 1 行目を置換えるには次のようにします。
$ find *.py | xargs sed -i '1c #!/usr/local/bin/python'
$ sed '1c 置換え後の内容'
find と組合せて、拡張子が .cgi であるファイルの 1 行目を置換えるには次のようにします。
$ find *.py | xargs sed -i '1c #!/usr/local/bin/python'
ちょっと前までは人間でも読解困難な文字を読ませていた CAPTCHA ですが、Google の reCAPTCHA v2 では人間である可能性が高い場合は「私はロボットではありません」というチェックを入れるだけとなって、かなりユーザへの負担が軽減されました。
既にクリックすら必要ない reCAPTCHA v3 のベータテストが行われているので、もしかしたらすぐに v3 へ移行してしまうかもしれませんが、現時点ではまだベータ版ということで v2 を選んでいます。
reCAPTCHA v2 を自分のサイトに導入するには、クライアントに表示されるページとサーバの両方にコードの追加が必要となります(実体は両方ともサーバにあるファイルですね)。
流れとしては下記の通りです。
https://www.google.com/recaptcha/ を開き、”My reCAPTCHA” から登録を行います。余談ですが右下に reCAPTCHA のマークが表示されているので、このページ自体も reCAPTCHA で保護されていますね。
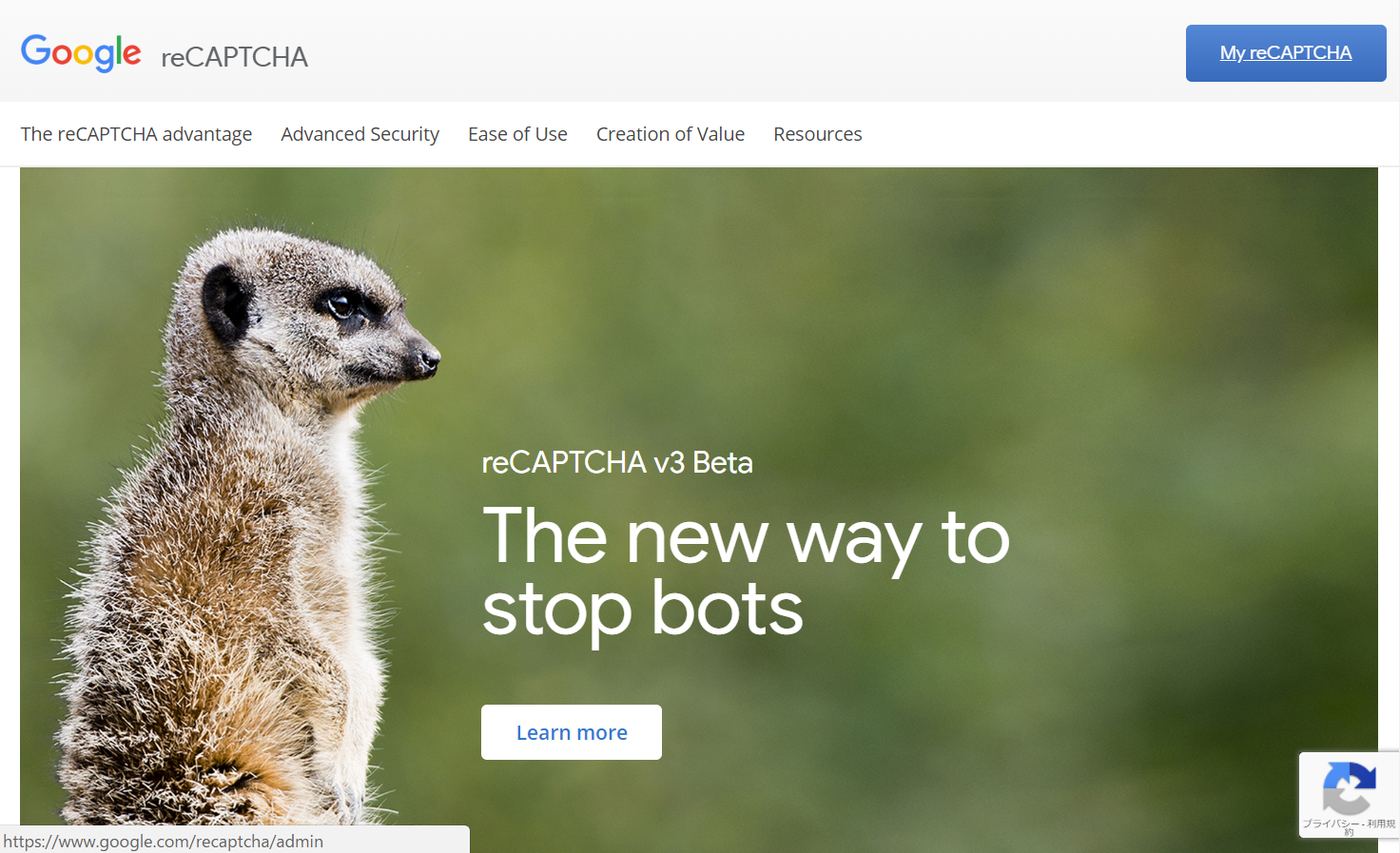
“Register a new site” から新しくサイトを登録します。自分の区別しやすい名前とドメイン名を入力するだけです。
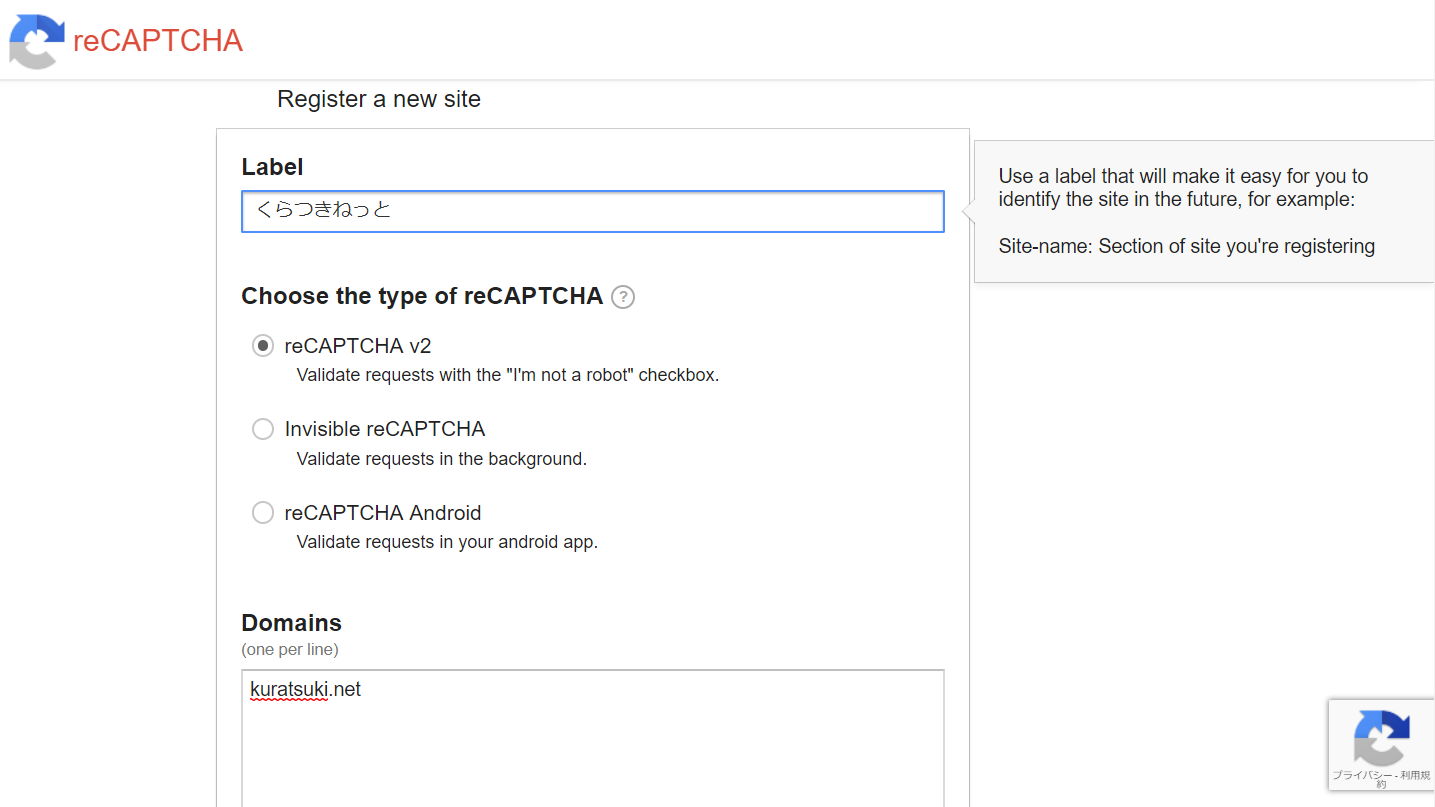
登録したサイトを開くと設定の仕方が載っているので、これを参考にソースやコードを書き換えます。癖で secret にモザイクかけてしまいましたが、HTML に書かれるから隠す意味はありませんね。
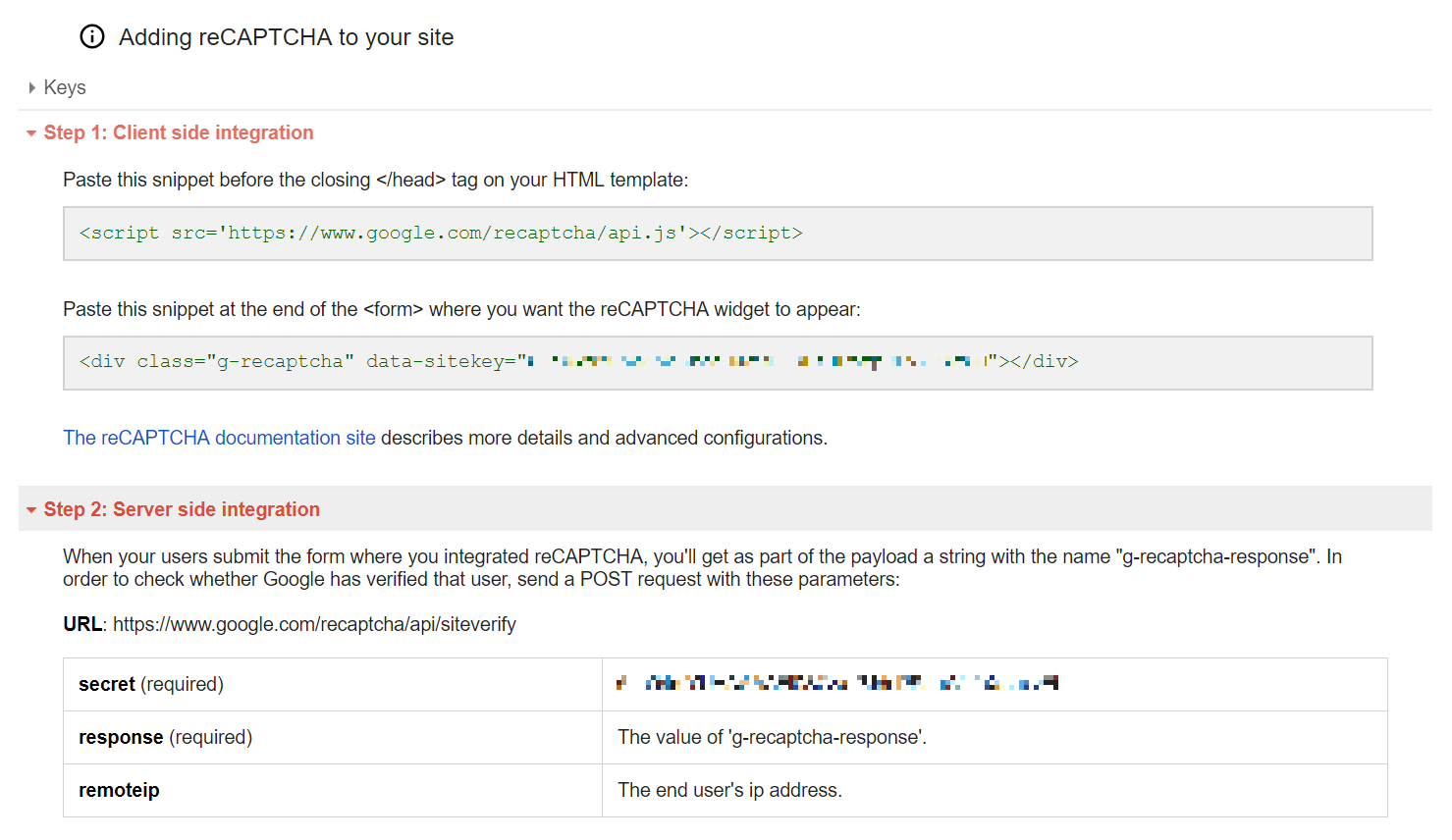
2 点だけです。
<script src='https://www.google.com/recaptcha/api.js'></script>
<div class="g-recaptcha" data-sitekey="XXXXXXXXYOURSECRETXXXXXXXXX"></div>
これが reCAPTCHA v2 のチェックボックスになります。
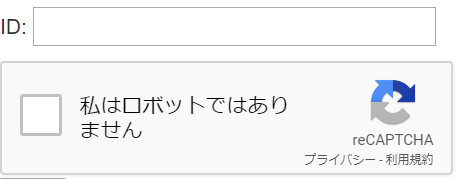
ここまでで次のような表示が現れたら OK です(ID: の入力欄は関係ありません)。
今回は昔ながらの手法で POST された form を読み取る CGI を対象としています。
使うモジュールは次の通り。
import cgi import urllib, urllib2 import json
cgi は form の値を読み取るために、urllib, urllib2 は Google の API にアクセスするために、json は API の返答を読み取るために使います。
後は通常の form のように ‘g-recaptcha-response’ の値を取得して、’https://www.google.com/recaptcha/api/siteverify’ に対して secret と ‘g-recaptcha-response’ の値を POST します。
# form から g-recaptcha-response の値を取得
form = cgi.FieldStorage()
response = form.getfirst('g-recaptcha-response', '')
# API で値を検証する
url = 'https://www.google.com/recaptcha/api/siteverify'
secret = 'XXXXXXXXYOURSECRETXXXXXXXXX'
params = urllib.urlencode({'secret': secret, 'response': response})
req = urllib2.Request(url, params)
res = json.loads(urllib2.urlopen(req).read())
# 検証結果
if res['success']:
# ここに reCAPTCHA 成功時の処理を書く
print('Passed reCAPTCHA')
else:
# ここに reCAPTCHA 失敗時の処理を書く
print('Failed to pass reCAPTCHA')
response は JSON で帰ってきますが、簡単に使うだけなら ‘success’ の値だけを取得すれば OK です。response の JSON は次のような内容を含んでいます(https://developers.google.com/recaptcha/docs/verify)。
{ "success": true|false, "challenge_ts": timestamp, // timestamp of the challenge load (ISO format yyyy-MM-dd'T'HH:mm:ssZZ) "hostname": string, // the hostname of the site where the reCAPTCHA was solved "error-codes": [...] // optional }
これだけなので、bot 対策に悩まされているなら試してみる価値はあります。
Python の bcrypt 実装にはいくつかあって、PyPI で検索すると単体で使うもの以外にも Flask 用、Django 用など様々なものがあります。
単体で使うには現在でもメンテが活発な bcrypt が良いと思いますが、導入する環境によっては libffi に依存する関係で pip install 中にビルドが通りません。環境を整えれば解決する話(apt なら install libffi-dev で OK)なのですが、共用サーバなのもあって他のもので解決できそうであればその方が良いと判断しました。
ここで注意しなければいけないのが、上に挙げた 3 つの bcrypt 実装は全て import bcrypt して使うことになっています。これはつまり、異なるライブラリなのに import する名前が bcrypt で同じなので、今どのライブラリを使っているのかが判断できなくて予想外の問題を起す可能性があるということです。
実際にこんな投稿がありました。
import bcrypt する場合は開発環境と運用環境の違いに十分注意しないと、一見動いているように見えてもこのようにハマる可能性が高いです。
試しに同じソースを使って、環境を bcrypt から py-bcrypt に変更してみました。
<type 'exceptions.TypeError'>: gensalt() got an unexpected keyword argument 'rounds'
args = ("gensalt() got an unexpected keyword argument 'rounds'",)
message = "gensalt() got an unexpected keyword argument 'rounds'"
gensalt() の引数が違うようです。
bcrypt の src/bcrypt/__init__.py を読んでみると、rounds と prefix があります。
def gensalt(rounds=12, prefix=b"2b"):
if prefix not in (b"2a", b"2b"):
raise ValueError("Supported prefixes are b'2a' or b'2b'")
if rounds < 4 or rounds > 31:
raise ValueError("Invalid rounds")
salt = os.urandom(16)
output = _bcrypt.ffi.new("char[]", 30)
_bcrypt.lib.encode_base64(output, salt, len(salt))
return (
b"$" + prefix + b"$" + ("%2.2u" % rounds).encode("ascii") + b"$" +
_bcrypt.ffi.string(output)
)
一方の py-bcrypt の bcrypt/__init__.py にある gensalt() の実装を見てみると、log_rounds だけです。
def gensalt(log_rounds = 12):
"""Generate a random text salt for use with hashpw(). "log_rounds"
defines the complexity of the hashing, increasing the cost as
2**log_rounds."""
return encode_salt(os.urandom(16), min(max(log_rounds, 4), 31))
以上から、bcrypt から py-bcrypt に移行するときは prefix をなくして rounds を log_rounds に直せば OK です。逆の場合は 2a を指定したいときだけ prefix = b’2a’ を与えれば良いです。py-bcrypt は 2a 固定になっていました。
hashpw() と checkpw() は特に変更することなく、正常に使えているようです。
古い OpenSSL が使われるのが原因です。Python ビルド時に新しい OpenSSL を指定すれば解決します。
$ pyenv uninstall 3.6.5 $ CPPFLAGS="-I/usr/local/ssl/include" LDFLAGS="-L/usr/local/ssl/lib" pyenv install 3.6.5
さくらのレンタルサーバーはプラン スタンダード以上で SSH が使えるので、pyenv を入れたり pip を入れたりできます。pyenv を使って Python の他のバージョンをインストールするときに注意しないといけないのが、さくらでは Python 導入時のビルドで古い OpenSSL が使われてしまうことです。これの影響で pip したときに次のような SSL のエラーを吐きます。
$ pip install bcrypt Collecting bcrypt Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/ Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/ Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/ Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/ Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/ Could not fetch URL https://pypi.python.org/simple/bcrypt/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.python.org', port=443): Max retries exceeded with url: /simple/bcrypt/ (Caused by SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)) - skipping Could not find a version that satisfies the requirement bcrypt (from versions: ) No matching distribution found for bcrypt
OpenSSL のバージョンが古いのかな?とバージョンを確認しても最新版です。
$ openssl version OpenSSL 1.0.2o 27 Mar 2018
ですが pyenv install 3.6.5 した Python 上で確認してみると
$ python Python 3.6.5 (default, Jun 26 2018, 10:35:21) [GCC 4.2.1 20070831 patched [FreeBSD]] on freebsd9 Type "help", "copyright", "credits" or "license" for more information. >>> import ssl >>> ssl.OPENSSL_VERSION 'OpenSSL 0.9.8zf 19 Mar 2015'
思いっきり 0.9.8zf と出ていますね。「Python – さくらレンタルサーバーでpip installができません(123028)|teratail」によると、普通にビルドすると最新版の OpenSSL ではなくて、古い方の OpenSSL をリンクしてしまうとのこと。
さくらレンタルサーバでは普通にpythonをbuildすると古いopensslにつながってしまうようです。
/usr/local/sslに新しいのが入ってるみたいなので、./configure CPPFLAGS="-I/usr/local/ssl/include" LDFLAGS="-L/usr/local/ssl/lib"でpythonを作るとよさそうです。
ということで一旦インストールした Python を uninstall して、OpenSSL のパスを指定して再度インストールし直します。
$ pyenv uninstall 3.6.5 $ CPPFLAGS="-I/usr/local/ssl/include" LDFLAGS="-L/usr/local/ssl/lib" pyenv install 3.6.5 Downloading Python-3.6.5.tgz... -> https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tgz Installing Python-3.6.5... Installed Python-3.6.5 to /home/USERNAME/.pyenv/versions/3.6.5
無事インストールできたようなので、OpenSSL のバージョンを確認してみます。
$ python Python 3.6.5 (default, Jun 26 2018, 10:35:21) [GCC 4.2.1 20070831 patched [FreeBSD]] on freebsd9 Type "help", "copyright", "credits" or "license" for more information. >>> import ssl >>> ssl.OPENSSL_VERSION 'OpenSSL 1.0.2o 27 Mar 2018'
大丈夫そうですね。pip の更新を兼ねて pip を試してみます。
$ pip install -U pip Collecting pip Downloading https://files.pythonhosted.org/packages/0f/74/ecd13431bcc456ed390b44c8a6e917c1820365cbebcb6a8974d1cd045ab4/pip-10.0.1-py2.py3-none-any.whl (1.3MB) 100% |################################| 1.3MB 890kB/s Installing collected packages: pip Found existing installation: pip 9.0.3 Uninstalling pip-9.0.3: Successfully uninstalled pip-9.0.3 Successfully installed pip-10.0.1
ばっちり動きました。
ですが……今回の目的だった bcrypt のインストールは、libffi がなくて結局できず。py-bcrypt なら pip 一発なのでソースコードを py-bcrypt に書き替えた方が早そう。ちょっと不完全燃焼です。
Python から PDF ファイルを作成できる ReportLab を試してみます。
ReportLab のインストールは pip で一発ですが
$ python -V Python 3.6.5 $ pip install reportlab ...<省略>... The headers or library files could not be found for jpeg, a required dependency when compiling Pillow from source.
と Pillow のインストール時に JPEG のヘッダ類がないと怒られるので、libjpeg-dev を apt でインストールしておきます。
$ sudo apt install libjpeg-dev $ pip install reportlab Collecting reportlab Using cached https://files.pythonhosted.org/packages/87/f9/53b34c58d3735a6df7d5c542bf4de60d699cfa6035e113ca08b3ecdcca3f/reportlab-3.4.0.tar.gz Collecting pillow>=2.4.0 (from reportlab) Using cached https://files.pythonhosted.org/packages/89/b8/2f49bf71cbd0e9485bb36f72d438421b69b7356180695ae10bd4fd3066f5/Pillow-5.1.0.tar.gz Requirement already satisfied: pip>=1.4.1 in /home/pi/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from reportlab) (10.0.1) Requirement already satisfied: setuptools>=2.2 in /home/pi/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from reportlab) (39.0.1) Installing collected packages: pillow, reportlab Running setup.py install for pillow ... done Running setup.py install for reportlab ... done Successfully installed pillow-5.1.0 reportlab-3.4.0
公式のユーザガイド(PDF)にあるサンプルコードを実行してみます。
from reportlab.pdfgen import canvas
def hello(c):
c.drawString(100,100,"Hello World")
c = canvas.Canvas("hello.pdf")
hello(c)
c.showPage()
c.save()
hello.pdf が生成されているはずなので開いて確認します。

簡単ですね。ただし、このままだと日本語を出力しようとしても四角(■)で埋められるだけでした。エンコーディングも関係ないようだったのでフォントを指定する必要があるようです。
座標系はページ左下を起点としています。先の例では左下から (100, 100) の座標に文字列を描画しています。
こちらを参考にしました。
ReportLab には予め HeiseiMin-W3, HeiseiKakuGo-W5 が用意されているそうです。ユーザガイドの 3.6 Asian Font Support に Asian Language Packs として記載されていますね。
Japanese, Traditional Chinese (Taiwan/Hong Kong), Simplified Chinese (mainland China) and Korean are all supported and our software knows about the following fonts:
- chs = Chinese Simplified (mainland): ‘STSong-Light’
- cht = Chinese Traditional (Taiwan): ‘MSung-Light’, ‘MHei-Medium’
- kor = Korean: ‘HYSMyeongJoStd-Medium’,’HYGothic-Medium’
- jpn = Japanese: ‘HeiseiMin-W3’, ‘HeiseiKakuGo-W5’
これらを参考に日本語を入れてみたのが次のソースになります。ファイルは UTF-8n で保存しています。
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A4, portrait
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.cidfonts import UnicodeCIDFont
c = canvas.Canvas('sample.pdf', pagesize=portrait(A4))
pdfmetrics.registerFont(UnicodeCIDFont('HeiseiKakuGo-W5'))
c.setFont('HeiseiKakuGo-W5', 24)
w, h = A4
c.drawCentredString(w / 2, h / 2, '日本語PDFのサンプルです。')
c.showPage()
c.save()

特に問題なく表示されていますね。
この他にも自分で TrueType フォントを用意して指定することもできます。試しに Windows 10 の游ゴシックを使ってみました。
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A4, portrait
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
c = canvas.Canvas('sample.pdf', pagesize=portrait(A4))
pdfmetrics.registerFont(TTFont('Yu Gothic Light', 'YuGothL.ttc'))
c.setFont('Yu Gothic Light', 24)
w, h = A4
c.drawCentredString(w / 2, h / 2, '日本語PDFのサンプルです。')
c.showPage()
c.save()

ばっちりです。*.ttf だけでなく *.ttc でも大丈夫でした。
ユーザガイドには次のように記載されています。
For the dedicated presentation of text in a PDF document, use a text object. The text object interface provides detailed control of text layout parameters not available directly at the canvas level. In addition, it results in smaller PDF that will render faster than many separate calls to the drawString methods.
テキストが多いなら、一回一回 drawString() を呼び出すよりもこちらを使えってことらしいです。が、いざ使ってみると canvas に beginText() なんてメソッドはないと言われて使えず。
textobject = canvas.beginText(x, y) canvas.drawText(textobject)
ここまでは低水準(low-level)の描画メソッドばかりでした。これらを駆使して複雑な文書を作れないこともないですが、大変な労力を要します。例えば改行や改頁といった処理も自分で行わないといけません。
ReportLab には Platypus というテンプレートエンジンが用意されいて、一般的な文書の構成であればわりと簡単にページの構成を作ることができます。
次はユーザガイドに載っている Platypus の最も簡単なサンプルを少しだけ整形したものです。
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.rl_config import defaultPageSize
from reportlab.lib.units import inch
PAGE_HEIGHT=defaultPageSize[1]; PAGE_WIDTH=defaultPageSize[0]
styles = getSampleStyleSheet()
Title = "Hello world"
pageinfo = "platypus example"
def myFirstPage(canvas, doc):
canvas.saveState()
canvas.setFont('Times-Bold',16)
canvas.drawCentredString(PAGE_WIDTH / 2.0, PAGE_HEIGHT - 108, Title)
canvas.setFont('Times-Roman',9)
canvas.drawString(inch, 0.75 * inch, "First Page / %s" % pageinfo)
canvas.restoreState()
def myLaterPages(canvas, doc):
canvas.saveState()
canvas.setFont('Times-Roman',9)
canvas.drawString(inch, 0.75 * inch, "Page %d %s" % (doc.page, pageinfo))
canvas.restoreState()
doc = SimpleDocTemplate("phello.pdf")
Story = [Spacer(1, 2 * inch)]
style = styles["Normal"]
for i in range(100):
bogustext = ("This is Paragraph number %s. " % i) * 20
p = Paragraph(bogustext, style)
Story.append(p)
Story.append(Spacer(1, 0.2 * inch))
doc.build(Story, onFirstPage=myFirstPage, onLaterPages=myLaterPages)
これによって生成された phello.pdf を表示すると、次のようになっています。


<執筆中>
$ python -V Python 3.6.5 $ sudo apt install unixodbc-dev $ pip install pyodbc
unixodbc-dev を入れておかないと pip でのインストール中にこけます。
connect = pyodbc.connect('DSN=SQLServer;UID=user;PWD=password;')
connect.setencoding('utf-8')
connect.cursor.execute('SELECT 列 FROM テーブル WHERE 番号 = 5;')
connect.setencoding() でエンコーディングを指定したら解決しました。
古い基幹システムに SQL Server 2008 が使われており、テーブル名やカラム名が全て日本語で構成されていた関係で、Linux 上の Python から接続するのにひと手間かかっていました。DB 自体は UTF-8 で処理されているので、Python 2 からはクエリを query.encode('utf-8') とすることでうまく処理できていました。さらっと書いていますが、Python にまだ慣れていないときに開発していたので、かなり苦労して辿りついた結論です。
今回は Bottle を使うに当って Python 3 に移行する関係から DB 接続周りを一新する必要があったのが事の始まりです。DB への接続自体は Python 2 と同じで特に問題もなかったのですが、いざ SELECT 分を execute してみると次のようなエラーを吐きました。
pyodbc.ProgrammingError: ('42S22', "[42S22] [FreeTDS][SQL Server]Invalid column name 'F'. (207) (SQLExecDirectW)")
このエラーには見覚えがあり、さらにカラム名は日本語で指定したはずなのに見慣れない文字になっていることから、日本語のエンコーディング周りの問題だろうということはすぐにわかりました。
まず試してみたのが Python 2 と同じ手法でクエリを encode(‘utf-8’) する方法です。これの結果は
TypeError: The first argument to execute must be a string or unicode query.
ユニコードでよこせと怒られてしまいました。なら最初はユニコードで渡してるからそれで良いのではないか。
次に疑ったのはファイルの文字コードを他のエンコーディングで保存していないかです。でもソースコード冒頭には # -*- coding: utf-8 -*- と記述した上で、間違いなく UTF-8N で保存しています。試しに Shift JIS で保存すると、次のエラーで実行すらできません。
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0x8f in position 0: invalid start byte
調べていても、そもそも Linux の Python から Windows Server の SQL Server を扱う事例自体が少なすぎて、情報があまり得られません。そこで、pyodbc のソースを読んでみようと思ったら、そのものずばりの情報がありました。
記事冒頭に書いた、DB に connect() した後 connection.setencoding('utf-8') するだけです。これで無事に日本語のテーブル名、列名を処理できました。
たった一文のことですが、情報量が少ないとこれに辿りついて気づくまでが本当に大変です。