{"success":true|false,"challenge_ts": timestamp,// timestamp of the challenge load (ISO format yyyy-MM-dd'T'HH:mm:ssZZ)"hostname":string,// the hostname of the site where the reCAPTCHA was solved"error-codes":[...]// optional}
def gensalt(log_rounds = 12):
"""Generate a random text salt for use with hashpw(). "log_rounds"
defines the complexity of the hashing, increasing the cost as
2**log_rounds."""
return encode_salt(os.urandom(16), min(max(log_rounds, 4), 31))
$ pip install bcrypt
Collecting bcrypt
Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Could not fetch URL https://pypi.python.org/simple/bcrypt/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.python.org', port=443): Max retries exceeded with url: /simple/bcrypt/ (Caused by SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)) - skipping
Could not find a version that satisfies the requirement bcrypt (from versions: )
No matching distribution found for bcrypt
OpenSSL のバージョンが古いのかな?とバージョンを確認しても最新版です。
$ openssl version
OpenSSL 1.0.2o 27 Mar 2018
ですが pyenv install 3.6.5 した Python 上で確認してみると
$ python
Python 3.6.5 (default, Jun 26 2018, 10:35:21)
[GCC 4.2.1 20070831 patched [FreeBSD]] on freebsd9
Type "help", "copyright", "credits" or "license" for more information.
>>> import ssl
>>> ssl.OPENSSL_VERSION
'OpenSSL 0.9.8zf 19 Mar 2015'
$ python
Python 3.6.5 (default, Jun 26 2018, 10:35:21)
[GCC 4.2.1 20070831 patched [FreeBSD]] on freebsd9
Type "help", "copyright", "credits" or "license" for more information.
>>> import ssl
>>> ssl.OPENSSL_VERSION
'OpenSSL 1.0.2o 27 Mar 2018'
$ python -V
Python 3.6.5
$ pip install reportlab
...<省略>...
The headers or library files could not be found for jpeg,
a required dependency when compiling Pillow from source.
ReportLab には予め HeiseiMin-W3, HeiseiKakuGo-W5 が用意されているそうです。ユーザガイドの 3.6 Asian Font Support に Asian Language Packs として記載されていますね。
Japanese, Traditional Chinese (Taiwan/Hong Kong), Simplified Chinese (mainland China) and Korean are all supported and our software knows about the following fonts:
chs = Chinese Simplified (mainland): ‘STSong-Light’
cht = Chinese Traditional (Taiwan): ‘MSung-Light’, ‘MHei-Medium’
kor = Korean: ‘HYSMyeongJoStd-Medium’,’HYGothic-Medium’
canvas.roundRect(x, y, width, height, radius, stroke=1, fill=0)
一行文字列(改行なし文字列)
canvas.drawString(x, y, text)
canvas.drawRightString(x, y, text)
canvas.drawCentredString(x, y, text)
テキストオブジェクト
ユーザガイドには次のように記載されています。
For the dedicated presentation of text in a PDF document, use a text object. The text object interface provides detailed control of text layout parameters not available directly at the canvas level. In addition, it results in smaller PDF that will render faster than many separate calls to the drawString methods.
# -*- coding: utf-8 -*-
from bottle import route, run
@route('/')
@route('/index')
def index():
return '<p>Home</p>'
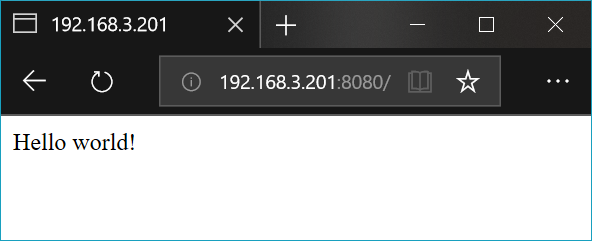
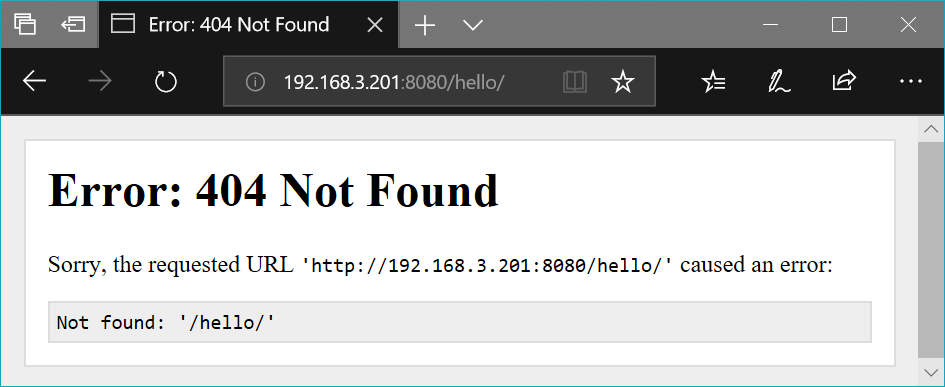
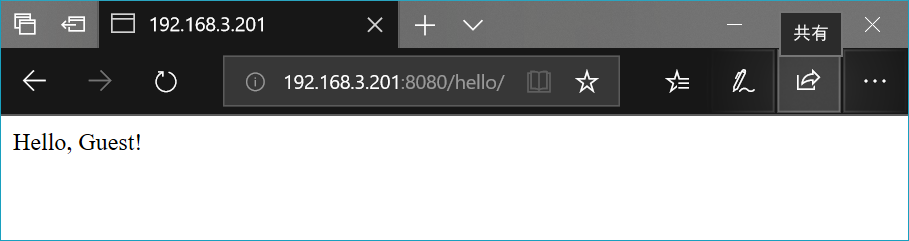
@route('/hello')
def hello():
return '<p>Hello!</p>'
run(host = '0.0.0.0', port = 8080)
これでページ分けが行えますね。
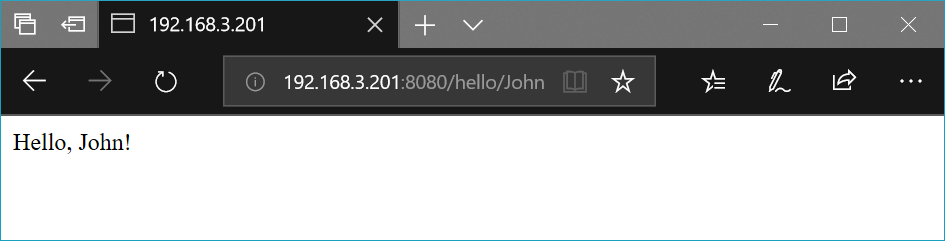
ここまでは予め用意した内容を出力しているだけですが、実際の Web アプリケーションではリクエストに応じて内容を変化させることがほとんどだと思います。クライアントからサーバへ情報を送るにはいくつか方法があります。例えば GET, POST, Cookie, … 等ですが、ルーティングの続きとして GET リクエストによるルーティングを試してみます。
# -*- coding: utf-8 -*-
from bottle import route, run, request
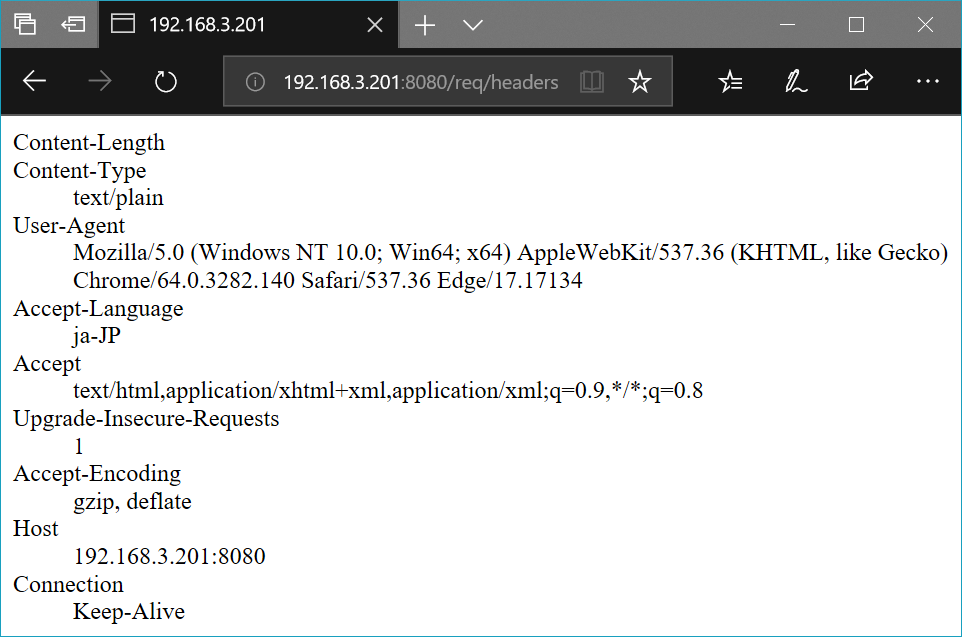
@route('/req/headers')
def req_headers():
ret = '<dl>'
for k in request.headers:
ret += '<dt>{}</dt><dd>{}</dd>'.format(k, request.headers.get(k))
ret += '</dl>'
return ret
run(host = '0.0.0.0', port = 8080)
# -*- coding: utf-8 -*-
from bottle import route, run, request, response
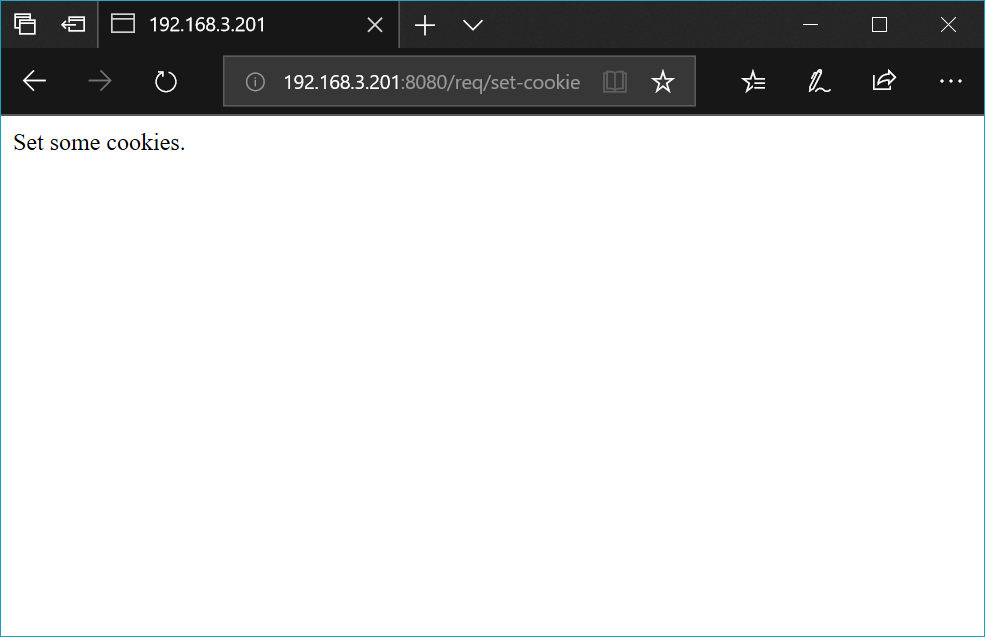
@route('/req/set-cookie')
def set_cookie():
response.set_cookie('foo', 'bar')
response.set_cookie('key', 'value')
return '<p>Set some cookies.</p>'
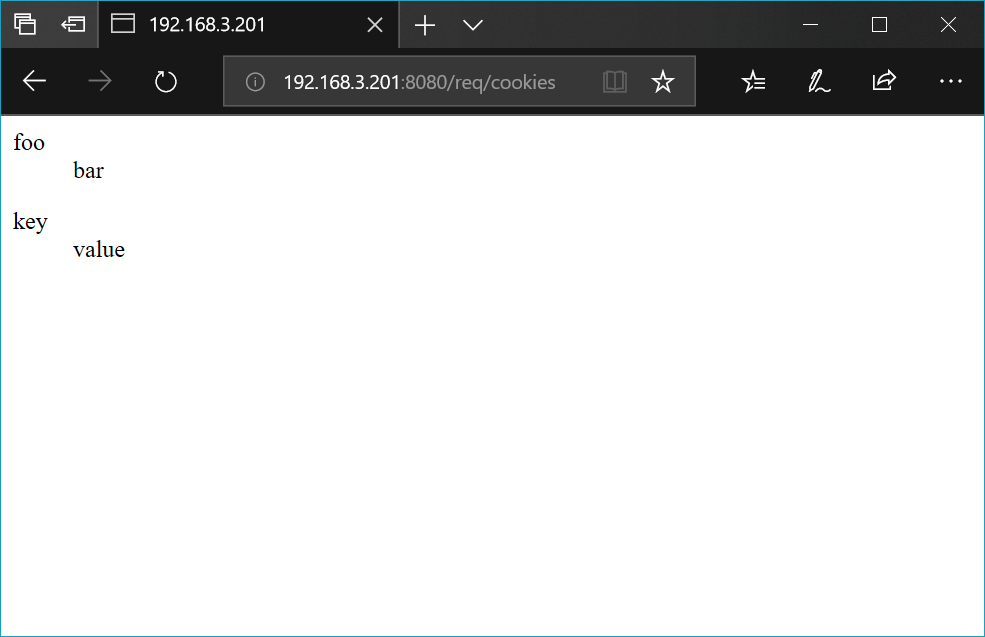
@route('/req/cookies')
def req_cookies():
ret = '<dl>'
for k in request.cookies:
ret += '<dt>{}</dt><dd>{}</dd>'.format(k, request.cookies.getunicode(k))
ret += '</dl>'
return ret
run(host = '0.0.0.0', port = 8080)
# -*- coding: utf-8 -*-
from bottle import route, post, run, request, response
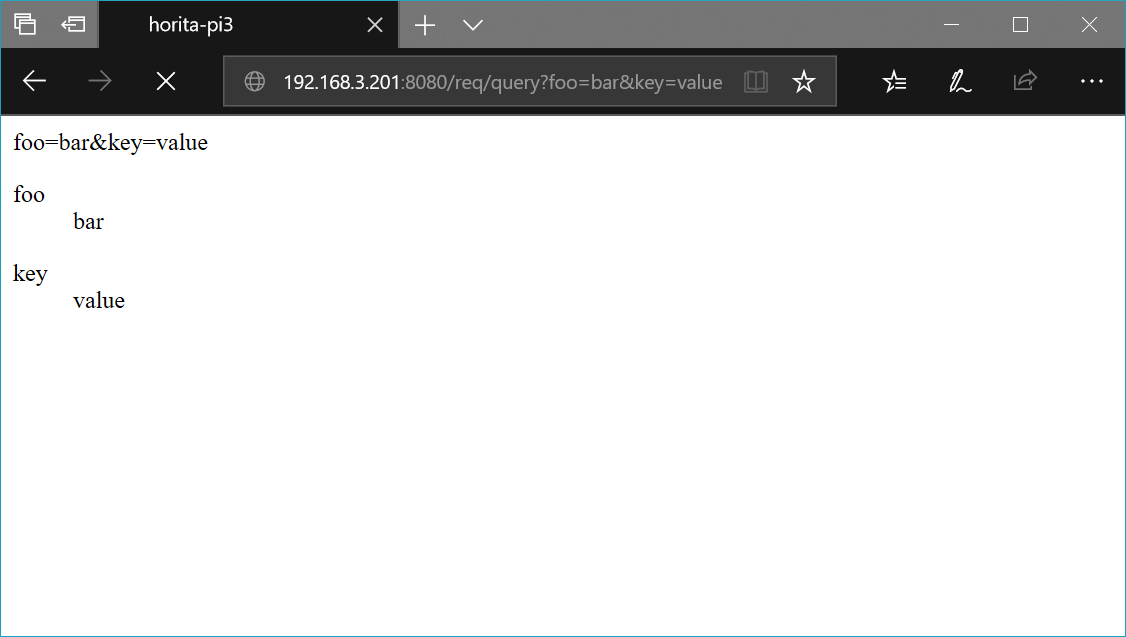
@route('/req/query')
def req_query():
ret = '<p>{}</p>'.format(request.query_string)
ret += '<dl>'
for k in request.query:
ret += '<dt>{}</dt><dd>{}</dd>'.format(k, request.query.getunicode(k))
ret += '</dl>'
return ret
run(host = '0.0.0.0', port = 8080)
例えば HTML であれば、DOCTYPE から始まるヘッダに相当する部分はどのページでもさほど違いはありません。title 要素の値が違うくらいでしょうか。これらを毎回出力するのは非効率的ですし、1 つの変更を適用させるためにすべての出力を書き換える必要ができます。CSS が普及するまで HTML に直接デザインを書き入れてたのと同じくらい非効率です。
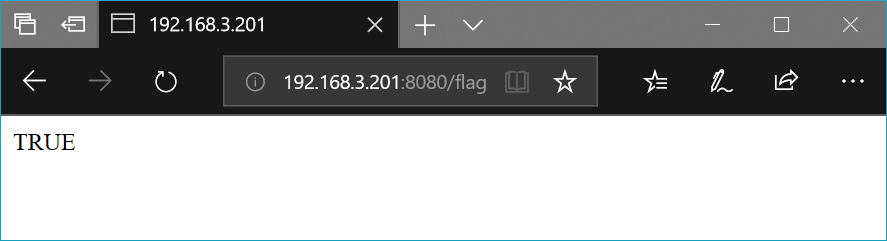
# -*- coding: utf-8 -*-
from bottle import template, route, run
@route('/flag')
def home():
return template('<p>{{"TRUE" if flag else "FALSE"}}</p>', flag = True)
run(host = '0.0.0.0', port = 8080)
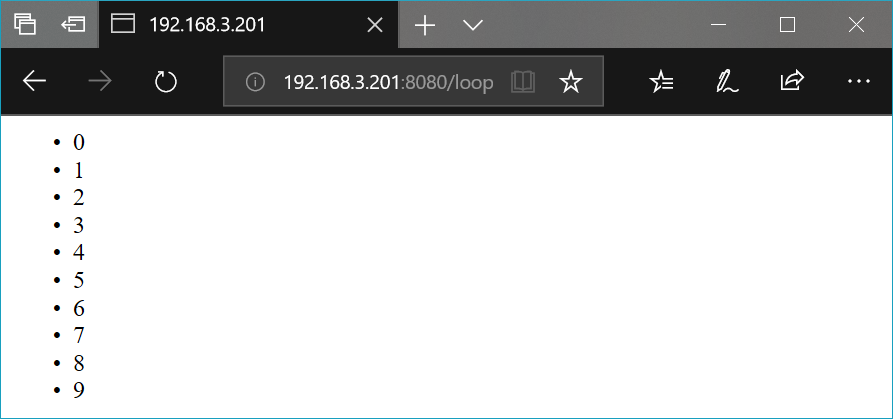
# -*- coding: utf-8 -*-
from bottle import template, route, run
@route('/loop')
def loop():
t = '''<ul>
% for count in range(10):
<li>{{count}}</li>
% end
</ul>'''
return template(t)
run(host = '0.0.0.0', port = 8080)
template: 埋め込みコード
テンプレートをファイルから読み込む
ここまでは、把握しやすいようにソースコードの中に直接 HTML を書いてテンプレートを記述していましたが、実際は別ファイルとして用意しないとテンプレートの意味がなくなってしまいます。