Excel で集計を行うときに使う「ピボットテーブル」という機能があります。複雑な集計表をマウス操作だけで作れるので、使い方によってはとても便利な機能です。
使ったことがない方に簡単に説明します。次のようなデータベースを考えます。
| 品目 | 産地 | 数量 | 単位 |
|---|---|---|---|
| りんご | 青森県 | 5 | 箱 |
| りんご | 長野県 | 30 | ヶ |
| りんご | 長野県 | 2 | 箱 |
| りんご | 青森県 | 10 | 箱 |
| みかん | 長崎県 | 7 | 箱 |
| みかん | 静岡県 | 120 | ヶ |
| みかん | 福岡県 | 50 | ヶ |
このデータから、都道府県と品目ごとの数量を集計するとします。ただし、集計するのは単位が「箱」のものだけ。すると次のような表になります。
| 単位:箱 | りんご | みかん |
|---|---|---|
| 青森県 | 15 | |
| 長野県 | 2 | |
| 長崎県 | 7 |
これを項目を選ぶだけで自動で生成してくれるのが、Excel のピボットテーブルです。
SQL だけでこのピボットを簡単に作る方法はないのかというと、SQL Server には PIVOT 句があって簡単に実現できます。Oracle にもあるようです。しかし、それ以外の MySQL, MariaDB, PostgreSQL, SQLite3 では PIVOT 句は今のところ無いようでした。無いからといってできないわけではなく、例えば次の記事のように色々と組み合わせればできないこともないようです。
記事を読まなくても SQL 文を見てもらえばわかると思いますが、よほど SQL だけで解決しないといけない状況でない限り、正直採りたくない手法です。どうせ SQL でデータを取得してからプログラム側で処理するのだから、プログラム側で処理すればいいと思い直したのが今回のお話です。
説明用に SQLite3 で次のようなデータベースを作成しました。
CREATE TABLE shipping (
id INTEGER PRIMARY KEY AUTOINCREMENT,
item TEXT NOT NULL,
qua INTEGER NOT NULL,
unit TEXT NOT NULL,
pref TEXT NOT NULL
);サンプルデータとして次の CSV を予め insert しておきます。
0,"いちご",10,"箱","岡山県"
1,"ぶどう",33,"個","長崎県"
2,"りんご",65,"箱","長野県"
3,"みかん",25,"箱","福岡県"
4,"ぶどう",2,"個","長野県"
5,"ぶどう",42,"個","長野県"
6,"いちご",31,"箱","岡山県"
7,"ぶどう",51,"箱","長崎県"
8,"りんご",79,"箱","福岡県"
9,"いちご",92,"箱","長崎県"
10,"ぶどう",40,"箱","岡山県"
11,"いちご",12,"箱","長崎県"
12,"いちご",56,"箱","長野県"
13,"いちご",11,"個","長野県"
14,"みかん",90,"個","山梨県"
15,"ぶどう",90,"個","長野県"
16,"みかん",44,"箱","岡山県"
17,"いちご",93,"箱","長崎県"
18,"りんご",13,"個","青森県"
19,"ぶどう",20,"個","長野県"
余談ですが、このデータは下記の Python スクリプトで生成させてます。
import random
item = ('りんご', 'みかん', 'ぶどう', 'いちご')
pref = ('青森県', '長野県', '山梨県', '岡山県', '福岡県', '長崎県')
unit = ('箱', '個')
for i in range(20):
print('{index},"{item}",{qua},"{unit}","{pref}"'.format(index = i, item = random.choice(item), pref = random.choice(pref), unit = random.choice(unit), qua = random.randrange(1, 100)))CSV を SQLite のデータベースに取り込むには、予めテーブルを用意した上でコマンドラインで .import FILE TABLE を実行します。SQLite の標準区切り子は “|” なので、CSV を読み込む前に “,” に変更しておく必要があります。
sqlite> .separator ,
sqlite> .import data.csv shipping
さて、肝心の Python プログラム側ですが、今回は実験も兼ねて SQL は完全にデータの取得だけ、処理は全て Python で行いました。
import sqlite3
# pivotのフィルタ
pivot_filter = 'unit'
pivot_filter_value = '箱'
# pivotする列と行と値
pivot_col = 'item'
pivot_row = 'pref'
pivot_val = 'qua'
# SQLite3からデータ取得
connect = sqlite3.connect('db.sqlite3')
connect.text_factory = str
connect.row_factory = sqlite3.Row
rows = connect.execute('SELECT * FROM shipping;').fetchall()
rows = [r for r in rows if r[pivot_filter] == pivot_filter_value]
# pivotの列項目と行項目
pivot_cols = {r[pivot_col] for r in rows}
pivot_rows = {r[pivot_row] for r in rows}
# pivot初期化
pivot = {row : {col : 0 for col in pivot_cols} for row in pivot_rows}
# pivot集計
for r in rows:
pivot[r[pivot_row]][r[pivot_col]] += r[pivot_val]
# pivot出力
# 列項目
for c in sorted(pivot_cols):
print('\t{}'.format(c), end = '')
print('')
# 一度行毎に出力
for r in sorted(pivot_rows):
# 行項目
print('{}'.format(r), end = '')
# 集計値
for c in sorted(pivot_cols):
print('\t{}'.format(pivot[r][c]), end = '')
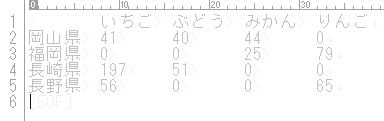
print('')これを先ほどのデータで実行した結果は次のようになりました。
いちご ぶどう みかん りんご
岡山県 41 40 44 0
福岡県 0 0 25 79
長崎県 197 51 0 0
長野県 56 0 0 65
タブ区切りのテキスト表示なのでちょっと見難いですが、ちゃんとピボットできていますね。
この記事はここで終了です、と書こうと思って、試しにデータを 100 万件にしてみたところ、処理がめちゃくちゃ遅いに気付いてしまいました。予想するに SQL で全てしてしまった方が圧倒的に速いのですが、それでは今回の目的である手間を最小にすることから外れてしまいます。なので出来る限り手間を掛けずに高速化できないか、試してみます。
高速化前
以下、先に挙げたランダムなデータ生成スクリプトで 100 万件のデータを用意し、SQLite3 に INSERT 済の状態での検証です。
$ time python3 pivot.py > result.txt
シェルで上記を 5 回実行し、その平均時間を処理時間とします。
- 22.426
- 22.441
- 22.789
- 22.366
- 22.335
高速化前は 22.471 秒となりました。
高速化 1 – フィルタ処理を SQL で
まずはすぐにでも思いつきそうな、Python のリスト内包表記で行っているフィルタ処理を SQL の WHERE 句で行う場合。ソースは差分だけ載せます。
rows = list(connect.execute('SELECT * FROM shipping WHERE {} = ?;'.format(pivot_filter), (pivot_filter_value, )).fetchall())- 13.371
- 13.327
- 13.226
- 13.336
- 13.227
平均 13.297 秒、約 9 秒の高速化。割合にすると 40% ですね。
高速化 2 – GROUP BY で集計
これもこの記事を書きながら思いついた方法。純粋にこの方法での影響を調べるために高速化 1 は一度元に戻して検証します。
rows = connect.execute('''
SELECT
{0}, {1}, {2}, SUM({3}) AS {3}
FROM
shipping
GROUP BY
{0}, {1}, {2};'''.format(
pivot_row, pivot_col, pivot_filter, pivot_val)
).fetchall()- 17.721
- 17.597
- 17.565
- 17.601
- 18.192
- 17.792
平均 17.749 秒、約 5 秒の高速化。約 20% の高速化です。
高速化 3 – 1 と 2 の組合せ
単純に高速化 1 と 2 を両方使います。
rows = list(connect.execute('''
SELECT
{0}, {1}, {2}, SUM({3}) AS {3}
FROM
shipping
WHERE
{2} = ?
GROUP BY
{0}, {1}, {2};'''.format(
pivot_row,
pivot_col,
pivot_filter,
pivot_val),
(pivot_filter_value, )
).fetchall())- 8.916
- 8.853
- 8.850
- 8.886
- 8.807
平均 8.862 秒、約 13 秒の高速化。60% の高速化です。
結論
わかりきったことですが、SQLite は速くて Python は遅いという結果になりました。楽を取るとか速さを取るか、それに尽きます。
Special Thanks
実装に当って、れお(@reoreo125)さんの多大なるご協力をいただきました。いつもありがとうございます。