ちょっと前までは人間でも読解困難な文字を読ませていた CAPTCHA ですが、Google の reCAPTCHA v2 では人間である可能性が高い場合は「私はロボットではありません」というチェックを入れるだけとなって、かなりユーザへの負担が軽減されました。
既にクリックすら必要ない reCAPTCHA v3 のベータテストが行われているので、もしかしたらすぐに v3 へ移行してしまうかもしれませんが、現時点ではまだベータ版ということで v2 を選んでいます。
reCAPTCHA v2 を自分のサイトに導入するには、クライアントに表示されるページとサーバの両方にコードの追加が必要となります(実体は両方ともサーバにあるファイルですね)。
流れとしては下記の通りです。
- reCAPTHA のページで登録を行う
- ユーザに表示する form にコードを埋め込む(JavaScript の読み込みと HTML)
- form からの値を Google に投げて判別するコードをサーバ側に追加する
reCAPTCHA の登録
https://www.google.com/recaptcha/ を開き、”My reCAPTCHA” から登録を行います。余談ですが右下に reCAPTCHA のマークが表示されているので、このページ自体も reCAPTCHA で保護されていますね。
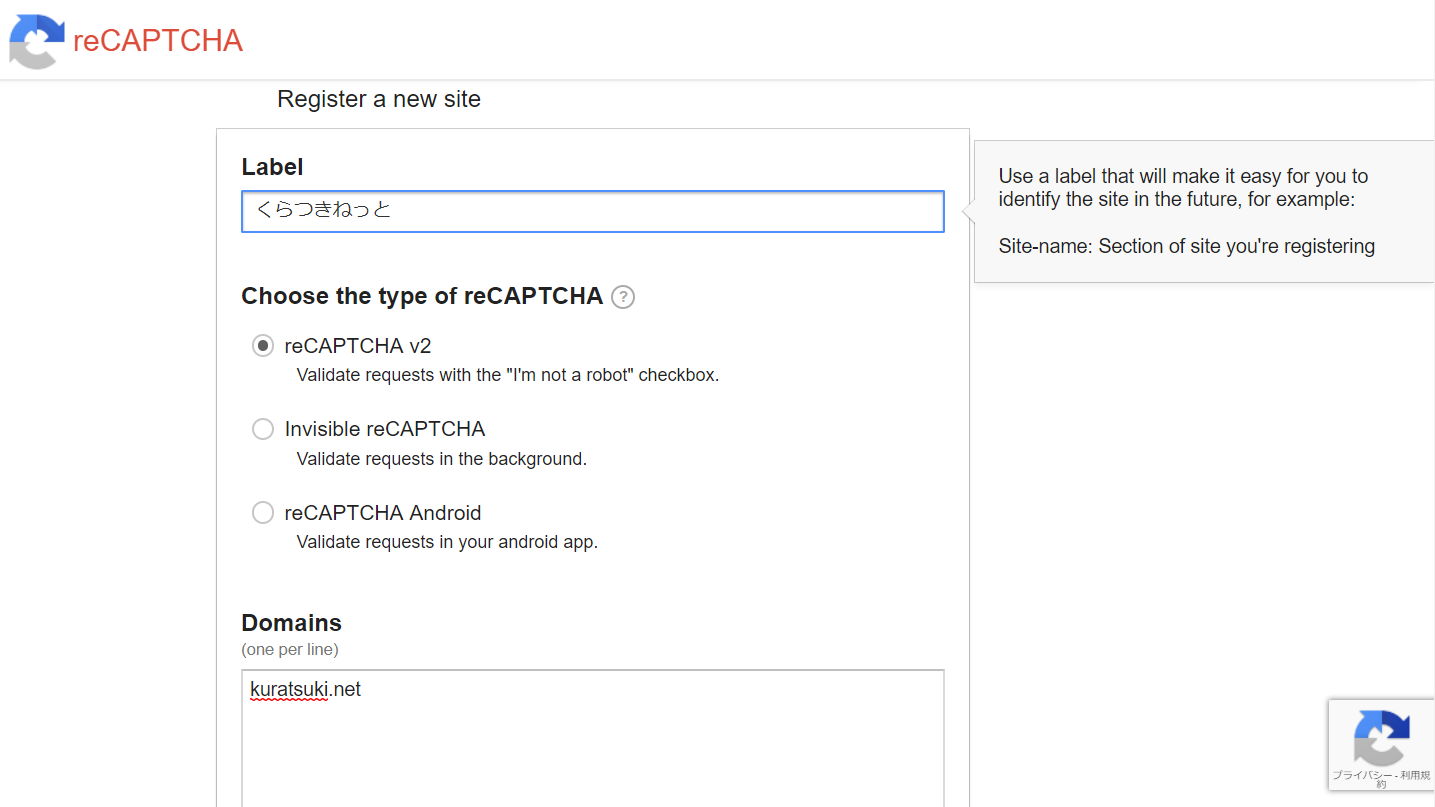
“Register a new site” から新しくサイトを登録します。自分の区別しやすい名前とドメイン名を入力するだけです。
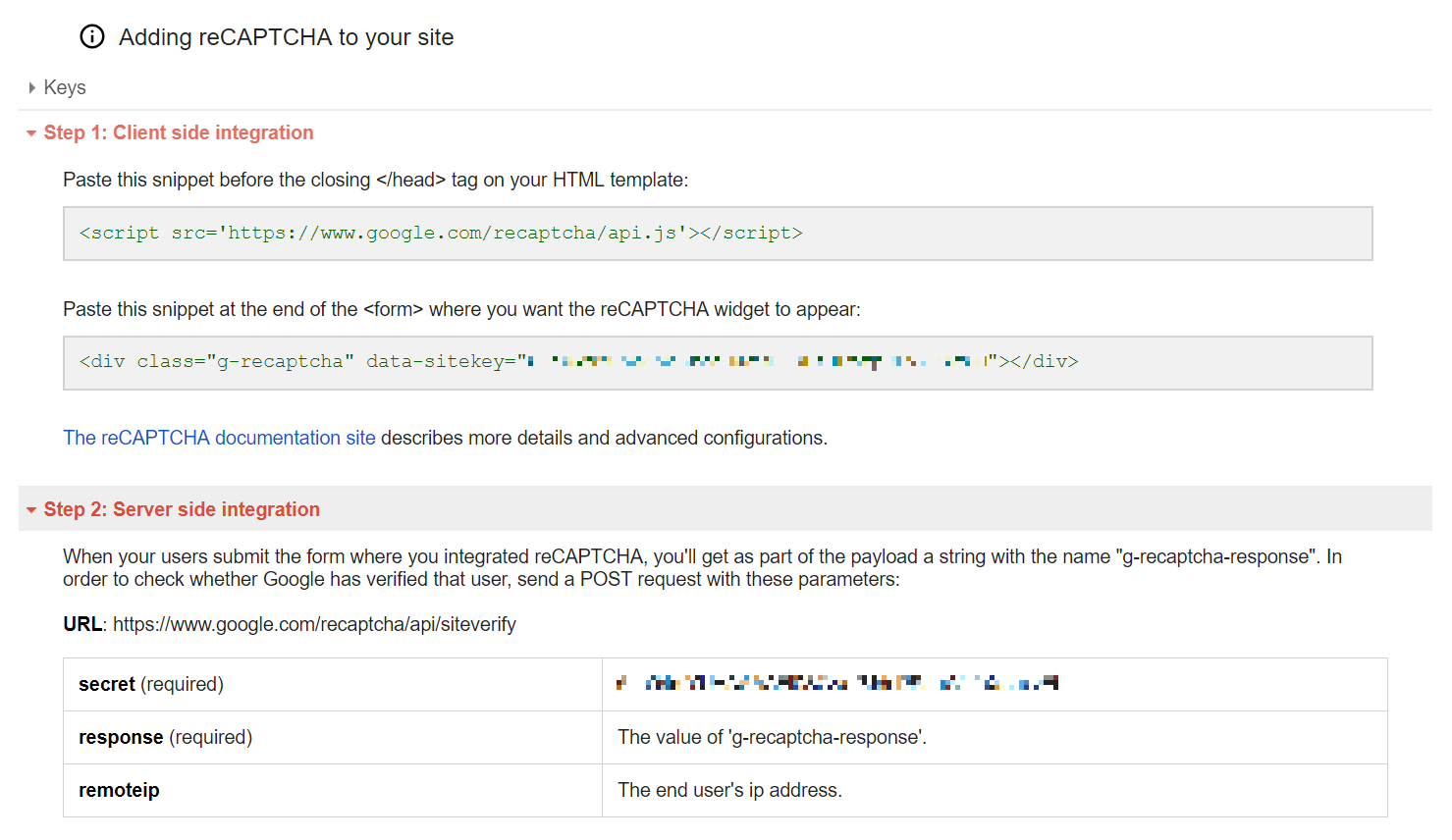
登録したサイトを開くと設定の仕方が載っているので、これを参考にソースやコードを書き換えます。癖で secret にモザイクかけてしまいましたが、HTML に書かれるから隠す意味はありませんね。
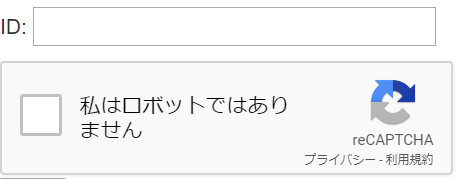
クライアントに表示される HTML の変更
2 点だけです。
head 要素に JavaScript の読み込みを追加
<script src='https://www.google.com/recaptcha/api.js'></script>
form 要素に div 要素を追加する
<div class="g-recaptcha" data-sitekey="XXXXXXXXYOURSECRETXXXXXXXXX"></div>
これが reCAPTCHA v2 のチェックボックスになります。
ここまでで次のような表示が現れたら OK です(ID: の入力欄は関係ありません)。
サーバ側 Python コードの修正
今回は昔ながらの手法で POST された form を読み取る CGI を対象としています。
使うモジュールは次の通り。
import cgi import urllib, urllib2 import json
cgi は form の値を読み取るために、urllib, urllib2 は Google の API にアクセスするために、json は API の返答を読み取るために使います。
後は通常の form のように ‘g-recaptcha-response’ の値を取得して、’https://www.google.com/recaptcha/api/siteverify’ に対して secret と ‘g-recaptcha-response’ の値を POST します。
# form から g-recaptcha-response の値を取得
form = cgi.FieldStorage()
response = form.getfirst('g-recaptcha-response', '')
# API で値を検証する
url = 'https://www.google.com/recaptcha/api/siteverify'
secret = 'XXXXXXXXYOURSECRETXXXXXXXXX'
params = urllib.urlencode({'secret': secret, 'response': response})
req = urllib2.Request(url, params)
res = json.loads(urllib2.urlopen(req).read())
# 検証結果
if res['success']:
# ここに reCAPTCHA 成功時の処理を書く
print('Passed reCAPTCHA')
else:
# ここに reCAPTCHA 失敗時の処理を書く
print('Failed to pass reCAPTCHA')
response は JSON で帰ってきますが、簡単に使うだけなら ‘success’ の値だけを取得すれば OK です。response の JSON は次のような内容を含んでいます(https://developers.google.com/recaptcha/docs/verify)。
{ "success": true|false, "challenge_ts": timestamp, // timestamp of the challenge load (ISO format yyyy-MM-dd'T'HH:mm:ssZZ) "hostname": string, // the hostname of the site where the reCAPTCHA was solved "error-codes": [...] // optional }
これだけなので、bot 対策に悩まされているなら試してみる価値はあります。