$ pip install bcrypt
Collecting bcrypt
Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)': /simple/bcrypt/
Could not fetch URL https://pypi.python.org/simple/bcrypt/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.python.org', port=443): Max retries exceeded with url: /simple/bcrypt/ (Caused by SSLError(SSLError(1, '[SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:833)'),)) - skipping
Could not find a version that satisfies the requirement bcrypt (from versions: )
No matching distribution found for bcrypt
OpenSSL のバージョンが古いのかな?とバージョンを確認しても最新版です。
$ openssl version
OpenSSL 1.0.2o 27 Mar 2018
ですが pyenv install 3.6.5 した Python 上で確認してみると
$ python
Python 3.6.5 (default, Jun 26 2018, 10:35:21)
[GCC 4.2.1 20070831 patched [FreeBSD]] on freebsd9
Type "help", "copyright", "credits" or "license" for more information.
>>> import ssl
>>> ssl.OPENSSL_VERSION
'OpenSSL 0.9.8zf 19 Mar 2015'
$ python
Python 3.6.5 (default, Jun 26 2018, 10:35:21)
[GCC 4.2.1 20070831 patched [FreeBSD]] on freebsd9
Type "help", "copyright", "credits" or "license" for more information.
>>> import ssl
>>> ssl.OPENSSL_VERSION
'OpenSSL 1.0.2o 27 Mar 2018'
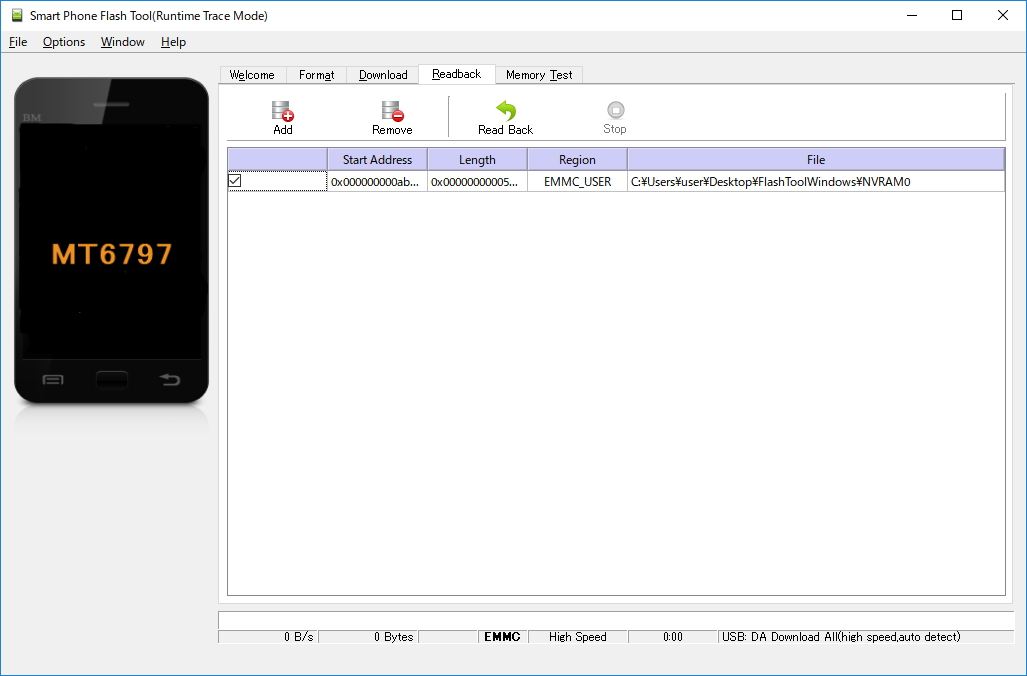
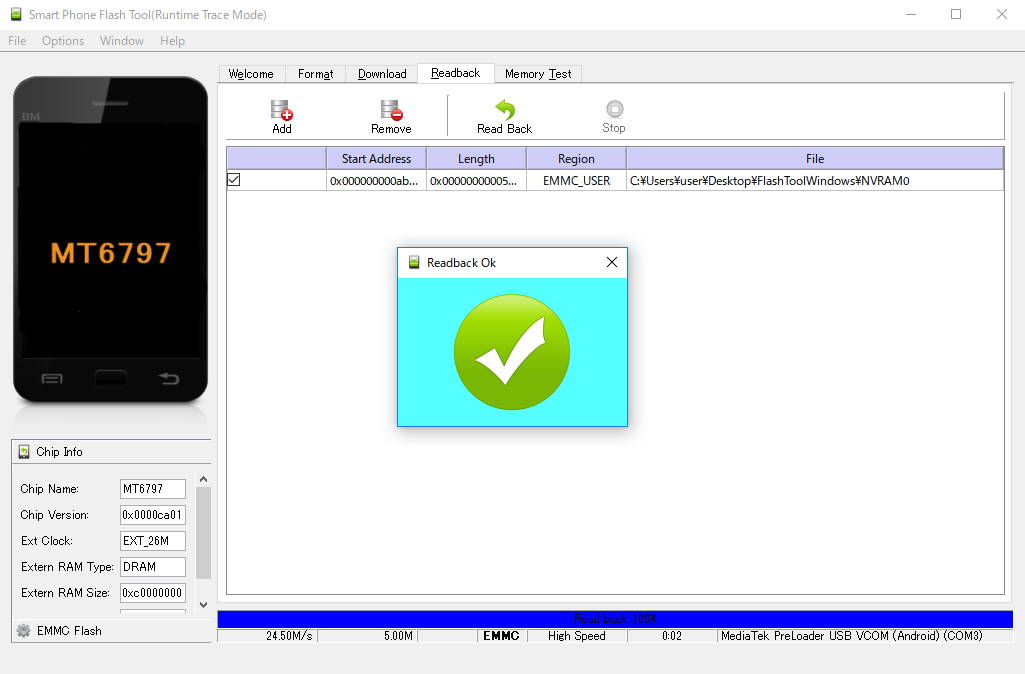
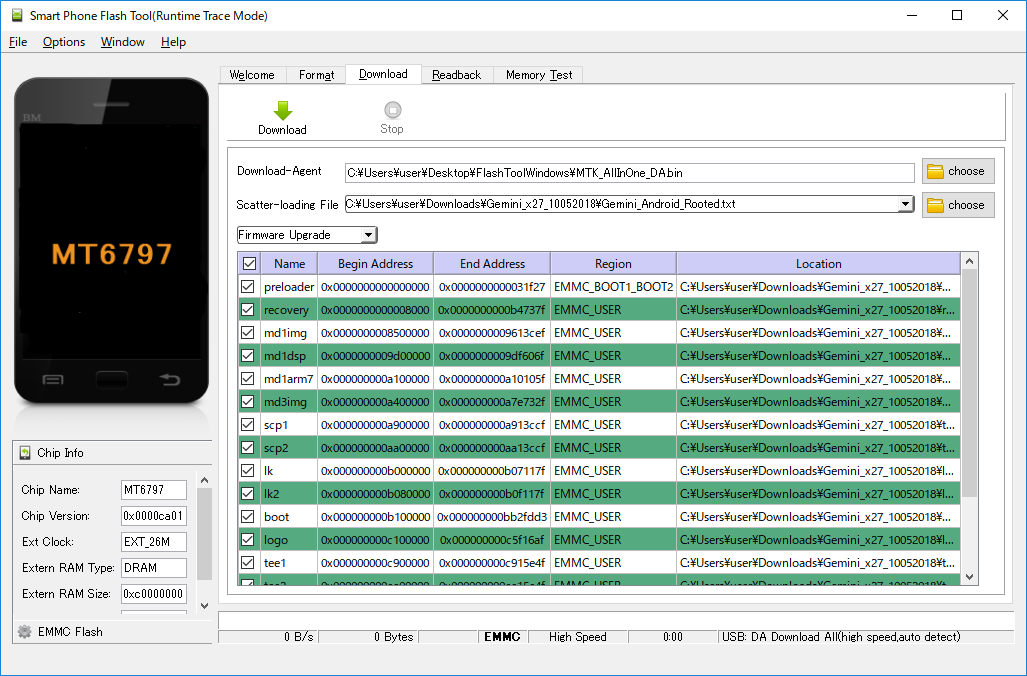
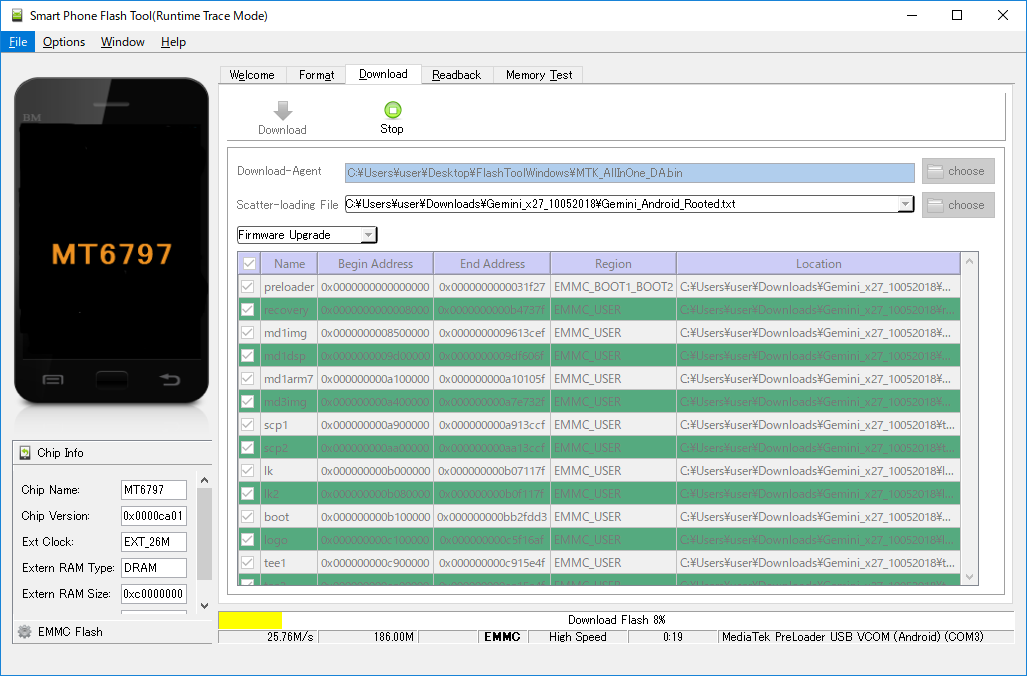
Before flashing the device with a different firmware it is a good idea to backup the current NVRAM partition. This partition stores key information for your Gemini, including the IMEI number. If it gets lost or damaged, your Gemini will not be able to take or receive calls.
$ python -V
Python 3.6.5
$ pip install reportlab
...<省略>...
The headers or library files could not be found for jpeg,
a required dependency when compiling Pillow from source.
ReportLab には予め HeiseiMin-W3, HeiseiKakuGo-W5 が用意されているそうです。ユーザガイドの 3.6 Asian Font Support に Asian Language Packs として記載されていますね。
Japanese, Traditional Chinese (Taiwan/Hong Kong), Simplified Chinese (mainland China) and Korean are all supported and our software knows about the following fonts:
chs = Chinese Simplified (mainland): ‘STSong-Light’
cht = Chinese Traditional (Taiwan): ‘MSung-Light’, ‘MHei-Medium’
kor = Korean: ‘HYSMyeongJoStd-Medium’,’HYGothic-Medium’
canvas.roundRect(x, y, width, height, radius, stroke=1, fill=0)
一行文字列(改行なし文字列)
canvas.drawString(x, y, text)
canvas.drawRightString(x, y, text)
canvas.drawCentredString(x, y, text)
テキストオブジェクト
ユーザガイドには次のように記載されています。
For the dedicated presentation of text in a PDF document, use a text object. The text object interface provides detailed control of text layout parameters not available directly at the canvas level. In addition, it results in smaller PDF that will render faster than many separate calls to the drawString methods.